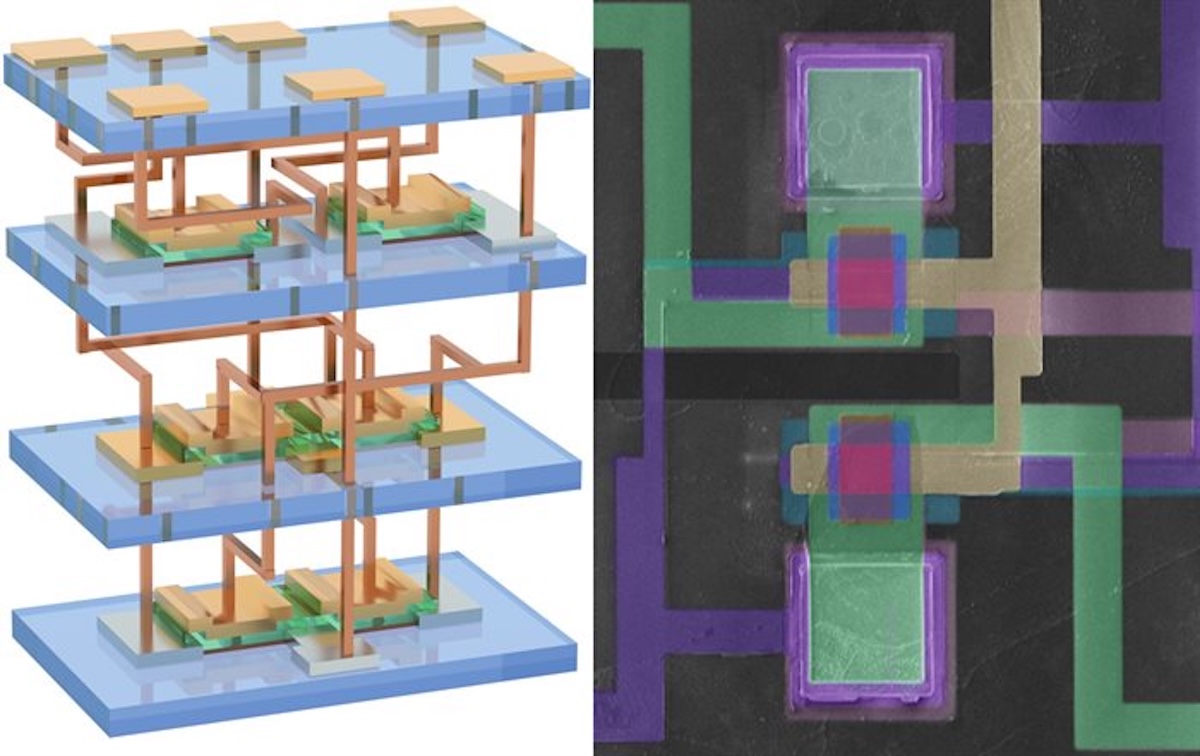
Des chercheurs de l’Université de l’Illinois à Urbana-Champaign ont démontré une approche radicalement différente de la miniaturisation des puces : fabriquer plusieurs couches de transistors en silicium directement superposées dans le même circuit, sans les assembler à partir de composants séparés. Le résultat, publié dans la revue Nature, comporte trois couches empilées de 625 transistors chacune, avec des taux de production de 98 à 100 % en salle blanche.
L’équipe, dirigée par le professeur Qing Cao, s’appuie sur une intégration monolithique 3D en silicium monocristallin. Plutôt que de fabriquer des puces séparément et de les assembler en packaging, les chercheurs construisent de nouvelles couches actives directement sur une couche déjà achevée. C’est une distinction importante : ce n’est pas de l’empilement de composants finis, c’est de la fabrication verticale en continu.
Ce qui diffère des chiplets, du HBM et du V-Cache 3D
Les techniques actuelles d’empilement — chiplets, HBM, V-Cache 3D — travaillent toutes à partir de composants fabriqués sur des wafers distincts, assemblés ensuite dans un packaging. Ces méthodes ont permis des gains considérables, mais elles restent contraintes par les limites des connexions inter-composants.
| Technologie | Ce qu’elle empile | Limite principale |
|---|---|---|
| Chiplets | Blocs complets fabriqués séparément | Connexions moins denses entre dies |
| HBM | Couches mémoire | Focalisé sur la mémoire, pas la logique |
| V-Cache 3D | Cache sur die CPU | Empilement post-fabrication |
| Intégration monolithique 3D | Couches de transistors dans un même circuit | Défis thermiques et de fabrication |
| Méthode Illinois | Nanomembranes silicium monocristallin | Phase de recherche |
L’intégration monolithique 3D va plus loin. Chaque couche de dispositifs se construit directement sur la précédente lors de la fabrication, ce qui autorise des connexions verticales bien plus denses — entre 10 et 100 fois plus que les via TSV utilisés pour relier des puces entières. Dans un circuit moderne, une part importante de la consommation et de la latence vient du déplacement de données entre blocs. Des connexions plus courtes et plus denses réduisent directement cet impact. Pour l’IA, le calcul haute performance et les mémoires cache, c’est un levier concret.
Le problème thermique résolu par des nanomembranes
Le principal obstacle à la fabrication de transistors superposés était la température. Obtenir du silicium cristallin de haute qualité requiert traditionnellement environ 1 000 °C, une chaleur qui dégraderait les métallisations et interconnexions des couches déjà fabriquées. L’industrie limite généralement le budget thermique post-fabrication à 400 °C. Des approches alternatives avec du silicium polycristallin ou des semi-conducteurs bidimensionnels existent, mais elles souffrent de limitations en performance, uniformité ou fiabilité.
L’équipe de l’Illinois a contournement ce problème avec des nanomembranes de silicium monocristallin de 10 nanomètres ou moins d’épaisseur. Ces feuilles, extraites d’une wafer donneuse, sont transférées par laminage à rouleaux sur un substrat contenant déjà la première couche de circuits. La température de liaison descend à 200 °C ou moins, bien en dessous du seuil critique. Le recours à des transistors sans jonction, dopés de manière uniforme avant empilement, élimine en plus le besoin d’un dopage à haute température après fabrication.
Trois couches, SRAM fonctionnel, densité de courant comparable au silicium standard
Les résultats ne se limitent pas à une démonstration de principe. Les trois couches empilées, chacune avec 625 transistors, affichent une bonne uniformité et des densités de courant comparables aux transistors silicium fabriqués sur wafer standard en haute température. Elles sont trois à quatre fois supérieures à celles des dispositifs monolithiques utilisant des matériaux alternatifs.
Surtout, l’équipe a connecté ces couches par des lignes métalliques verticales et démontré des circuits logiques 3D et des cellules SRAM fonctionnelles. Ce point est décisif : superposer du matériau semi-conducteur ne sert à rien si les couches ne peuvent pas communiquer efficacement pour former des circuits complexes. L’Illinois montre que c’est possible.
Qing Cao illustre l’enjeu avec une analogie directe : une cellule SRAM nécessite six transistors sur un même plan pour stocker un bit. Avec l’intégration verticale, ces transistors se répartissent sur plusieurs couches. On passe d’une ville dense à plat à des immeubles en hauteur : même fonction, empreinte réduite, communication interne accélérée.
Loi de Moore : la verticalité comme troisième dimension
La loi de Moore ralentit depuis une décennie. La miniaturisation approche des limites physiques où les effets quantiques, la variabilité et les coûts de fabrication freinent les gains. Construire en hauteur n’est pas une alternative à la miniaturisation : c’est une dimension supplémentaire. Au lieu de concentrer toutes les fonctions sur une surface plane, on répartit la logique et la mémoire sur plusieurs couches, on réduit la longueur des interconnexions et on augmente la densité sans dépendre uniquement de la réduction latérale.
Pour l’IA, cet aspect est particulier pertinent. Les acclérateurs actuels sont souvent bottleneckés par le déplacement de données entre mémoire, caches et unités de calcul. Une mémoire et une logique intégrées verticalement avec des connexions très denses ouvrent la voie à des architectures où la bande passante interne n’est plus le facteur limitant. C’est exactement le problème que cherche à résoudre l’architecture de nouvelles générations de processeurs comme la CPU NVIDIA Vera, où la bande passante mémoire est crítique pour l’IA agissante.
Cette recherche ne concurrence pas les chiplets ou le HBM : elle s’y ajoute. L’avenir combinera probablement plusieurs techniques. La scalabilité en 2D continue d’être travaillée à chaque nœud. L’empilement monolithique ajoute une dimension. Le packaging 3D et les systèmes hétérogènes complètent. Ces demandes croissantes se combinent aussi à une pression sur les ressources de fabrication, comme on le voit avec la tension sur les prix du stockage NAND due à l’IA.
Ce qu’il reste à résoudre avant la production industrielle
La prudence s’impose sur le calendrier. Cette technologie reste en phase de recherche. Scalabilité à des wafers plus grands, compatibilité avec les lignes de fabrication industrielles, gestion des défauts, intégration complète de la métallisation, optimisation thermique, développement d’outils EDA, tests de fiabilité à long terme, maîtrise des coûts : autant de défis réels. L’équipe travaille sur le transfert vers une fabrication industrielle, mais aucune date n’est avancée.
Ce qui est encourageant, c’est que le procédé s’appuie sur du silicium standard plutôt que sur des matériaux exotiques. Cela facilite l’adoption à grande échelle si les problèmes de scalabilité sont résolus. Le prochain saut en densité ne viendra peut-être pas uniquement de transistors plus petits, mais aussi de transistors empilés en hauteur.
Questions fréquentes
Que démontre la recherche de l’Université de l’Illinois ?
Une méthode pour empiler directement trois couches de transistors en silicium monocristallin dans le même circuit, avec un budget thermique de 200 °C ou moins grâce à des nanomembranes ultrafines. Les résultats ont été publiés dans Nature.
En quoi cette technique diffère-t-elle des chiplets ou du HBM ?
Les chiplets et le HBM intègrent des composants fabriqués séparément. L’intégration monolithique 3D construit de nouvelles couches de transistors directement sur des couches déjà achevées, avec des connexions verticales 10 à 100 fois plus denses que les TSV classiques.
Pourquoi la basse température est-elle indispensable ?
Les couches inférieures ont déjà des métallisations qui ne supportent pas 1 000 °C. La méthode des nanomembranes fonctionne à 200 °C ou moins, ce qui préserve l’intégrité des couches précédentes.
Quand cette technologie sera-t-elle disponible commercialement ?
Pas avant plusieurs années. Des défis majeurs de scalabilité, fiabilité et fabrication industrielle restent à résoudre. L’équipe de l’Illinois travaille à un transfert vers la production, sans calendrier précis annoncé.
Quel impact sur les puces d’IA ?
Des connexions verticales beaucoup plus denses entre logique et mémoire réduiraient la latence et la consommation liées au mouvement de données, qui est l’un des goulots d’étranglement actuels dans les acclérateurs d’IA.
Sources : Université de l’Illinois / Nature
