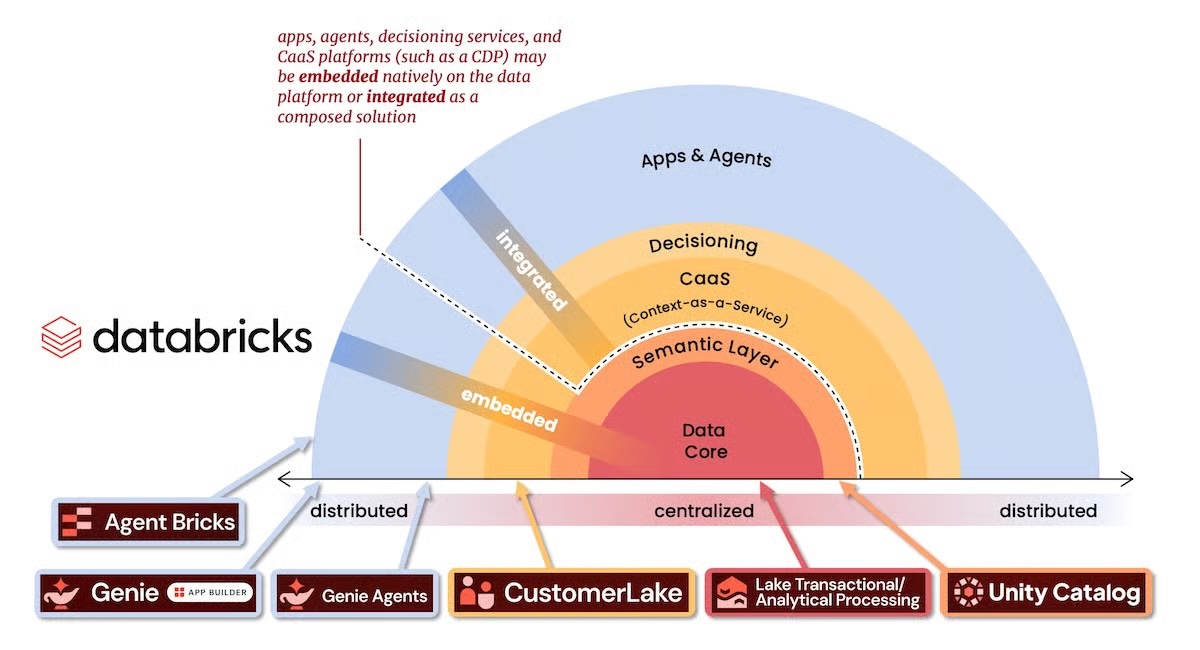
Databricks vient de faire un mouvement stratégique qui pourrait bouleverser l’équilibre du marketing technologique. Avec CustomerLake, l’entreprise a présenté une plateforme de gestion de données clients (CDP) agentique, intégrée nativement dans son lakehouse, offrant des capacités de Customer 360, résolution d’identités, création d’audiences, automatisation de campagnes, activation et personnalisation. La véritable nouveauté ne réside pas seulement dans l’ajout d’un nouvel outil marketing, mais dans l’intégration de cette couche directement dans l’infrastructure de données où résident déjà les modèles, la gouvernance et une grande partie du contexte métier.
Depuis des années, le CDP occupait une place intermédiaire dans l’architecture MarTech. Il recevait des données provenant du CRM, du e-commerce, de l’analyse, du support client, de la publicité et d’autres sources ; il unifiait ces données, constituait des profils, puis activait des audiences vers des outils tiers. Ce modèle a permis de résoudre de nombreux problèmes, mais a aussi engendré d’autres défis : duplication des données, pipelines, synchronisations, coûts supplémentaires, latences, règles de gouvernance dispersées et une dépendance constante aux intégrations.
CustomerLake propose une approche plus audacieuse : si les données résident déjà dans le lakehouse, pourquoi en faire une entité séparée ? Et si les agents d’intelligence artificielle doivent opérer sur des données gouvernées, à jour et connectées à des modèles, des métriques et des règles métier, faire migrer le contexte vers une autre couche devient inutile et contre-productif.
De CDP traditionnel à CDP intégrée
Databricks décrit CustomerLake comme une plateforme de gestion de données clients agentique, intégrée directement à sa plateforme. Selon l’entreprise, le produit intègre des Profile Agents pour transformer les données brutes en profils Customer 360 prêts pour le business, et des Campaign Agents pour créer des audiences, recommander des actions suivantes, activer les canaux et ajuster continuellement les campagnes en fonction des objectifs de l’entreprise.
Cette évolution s’inscrit dans une logique que le secteur préparait depuis plusieurs années. D’abord, les CDP classiques cherchaient à centraliser le profil client dans une plateforme indépendante. Ensuite, sont arrivés les CDP modulaires et l’approche « zéro-copie », axée sur le travail direct sur le data warehouse ou lakehouse sans dupliquer toutes les données ailleurs. CustomerLake pousse cette logique encore plus loin : il ne se contente pas de se connecter au dépôt de données, il est né à l’intérieur même de celui-ci.
| Modèle | Lieu de stockage des données | Avantage principal | Problème fréquent |
|---|---|---|---|
| CDP traditionnel | Plateforme CDP séparée | Unification des profils et des audiences pour le marketing | Duplication des données, ajout d’une couche de gouvernance |
| CDP modulaire | Sur le data warehouse ou lakehouse du client | Réduction des copies, utilisation directe des données | Dépendance aux outils externes et reverse ETL |
| CustomerLake / CDP intégrée | À l’intérieur du Lakehouse de Databricks | Fusionne données, agents, modèles et gouvernance dans une même plateforme | Renforce la dépendance à la plateforme de données |
| Activation MarTech classique | Dans les outils de marketing et d’engagement | Spécialisation par canal et expérience utilisateur | Fragmentation et synchronisations continues |
L’aspect le plus critique concerne la gouvernance. CustomerLake s’appuie sur Unity Catalog, la couche de gouvernance des données et de l’intelligence artificielle de Databricks. Cela permet aux agents marketing d’opérer sous des permissions, des contrôles et une sémantique métier déjà définis dans la plateforme. Pour beaucoup d’organisations, cette simplification peut s’avérer plus précieuse qu’une nouvelle fonction de segmentation : moins de règles dupliquées, moins de flux de données sensibles circulant via des outils externes et moins de points potentiels de rupture de traçabilité.
Une infrastructure qui s’impose dans le paysage MarTech
Ce mouvement reflète une dynamique claire en termes d’entreprise. Databricks ne joue plus seulement le rôle de fournisseur d’infrastructure de données, mais devient un concurrent direct dans une couche applicative qui appartenait historiquement au domaine du MarTech. Scott Brinker, une des voix les plus influentes du secteur, résumait cela comme le moment où l’infrastructure progresse pour s’immiscer dans la couche applicative. Selon lui, CustomerLake peut construire des profils Customer 360, affiner des segments, résoudre des identités et activer la personnalisation en temps réel, tout en étant nativement intégré à Databricks et opérant sous Unity Catalog.
Ce changement complique la donne pour les CDP indépendants. Il ne signifie pas leur disparition immédiate. Au contraire, Databricks pourrait revitaliser cette catégorie en la plaçant au cœur de l’architecture de données. Mais il exige que les fournisseurs MarTech expliquent clairement la valeur ajoutée quand la plateforme de données offre déjà des profils, agents, audiences, activation et gouvernance.
De nombreuses entreprises continueront probablement à utiliser des outils spécialisés pour l’email, la publicité, le commerce, le support client, les parcours client, l’expérimentation, le CRM ou la fidélisation. Le marché ne va pas se transformer soudainement en une plateforme unique. Cependant, le centre de gravité peut évoluer : si les données gouvernées résident dans le lakehouse et que les agents y opèrent, les applications externes deviennent des canaux, interfaces ou couches d’expérience, mais ne restent pas forcément le lieu où se définit l’intelligence client.
Les « Infinity Campaigns » : qu’est-ce que c’est ?
Databricks évoque le concept d’Infinity Campaigns pour désigner des campagnes continues et agentiques, qui ne se limitent pas à une audience statique, une règle et une date d’envoi. La promesse : que les agents analysent en permanence les signaux du client, recommandent l’action suivante optimale, activent des expériences sur différents canaux et ajustent leurs décisions en fonction des résultats.
Cette approche répond à une réalité : les acheteurs commencent aussi à utiliser des agents. Si un client délègue une partie de sa recherche, de la comparaison ou de la décision à des systèmes automatisés, alors le marketing basé sur des campagnes traditionnelles, segmentées, avec des règles manuelles, devient moins efficace. Le défi consiste à opérer dans un contexte dynamique, où il faut comprendre qui est le client, ce qu’il essaie de faire à cet instant précis, quels sont les objectifs de l’entreprise, ce qui a été tenté auparavant, et quelles sont les contraintes en place.
Ce contexte ne se limite pas au profil client. Il inclut aussi des règles métier, l’inventaire, les marges, la disponibilité, le support, l’historique des décisions, les signaux en temps réel et les données produits. C’est pourquoi Databricks parle d’évoluer du « golden record » vers le « golden context » : il ne suffit plus de connaître qui est la personne, il faut aussi comprendre ce qui se passe autour d’elle et ce que l’entreprise peut faire à cet instant précis.
Déjà vu : Snowflake, BigQuery et Fabric
La question qui se pose immanquablement est : comment réagiront les autres grandes platforms de données ? Snowflake, Google BigQuery et Microsoft Fabric rivalisent déjà pour devenir la base de la donnée, de l’analyse et de l’intelligence artificielle des entreprises. Si Databricks prouve qu’il peut absorber une partie des fonctionnalités du CDP, les autres seront probablement poussés à développer leurs propres capacités, nouer des alliances stratégiques ou intégrer des couches natives pour l’activation.
Snowflake bénéficie déjà d’un écosystème solide autour du partage de données, des « clean rooms », des applications et de l’analyse marketing. Google peut connecter BigQuery à ses activités publicitaires, à ses modèles Gemini et à ses outils cloud. Microsoft Fabric a un atout naturel dans les entreprises fortement implantées dans Dynamics, Power Platform, Azure et Microsoft 365. La trajectoire semble claire : la plateforme de données veut dépasser le simple stockage pour devenir un système d’exploitation pour les agents métier.
Pour les équipes marketing, cela impose une révision sérieuse de l’architecture. Il ne suffit plus de se demander quel CDP offre la meilleure interface ou le plus grand nombre de connecteurs. Il faut désormais analyser où résident les données maîtresses, qui en détient la gouvernance, comment les identités sont résolues, quels sont les coûts de déplacement des données, la latence d’activation, et si les agents peuvent opérer avec un contexte fiable.
CustomerLake ne supprime pas la complexité du marketing, il la déplace vers une autre couche. Elle réduit la friction liée aux données et à la gouvernance, mais requiert une maturité technologique dans Databricks, des modèles bien conçus, une qualité de données rigoureuse, des règles claires et une collaboration étroite entre marketing, data, technologie et métier.
Ce lancement laisse entrevoir une idée puissante : l’infrastructure ne souhaite plus simplement soutenir le MarTech, elle veut aussi participer activement aux processus de décision, d’activation et de personnalisation. Pour beaucoup de marques, cela peut signifier moins de couches, plus de contrôle. Pour les fournisseurs MarTech traditionnels, c’est un avertissement : leur futur concurrent principal pourrait ne pas être un autre CDP, mais la plateforme de données sur laquelle ils s’appuient eux-mêmes.
Questions fréquentes
Qu’est-ce que Databricks CustomerLake ?
CustomerLake est une plateforme de gestion de données clients agentique intégrée dans Databricks. Elle combine Customer 360, résolution d’identités, segmentation, automatisation, activation et personnalisation, le tout dans un lakehouse gouverné par Unity Catalog.
Soutient-elle les CDP traditionnels ?
Pas nécessairement, mais elle concurrence une partie de leurs fonctions. Elle peut diminuer la nécessité de disposer d’un CDP séparé dans les entreprises où les données, modèles et gouvernance sont déjà centralisés dans Databricks.
Quelle différence entre un CDP modulaire et CustomerLake ?
Un CDP modulaire fonctionne sur les données du warehouse ou du lakehouse, mais reste une solution externe. CustomerLake est intégré directement dans Databricks, avec des agents et une gouvernance unifiée dans la même plateforme.
Quel impact pour Snowflake, BigQuery ou Microsoft Fabric ?
CustomerLake établit un nouveau standard. D’autres fournisseurs de données pourraient être incités à lancer leurs propres capacités CDP, à forger des alliances ou à intégrer des couches d’applications auparavant réservées au MarTech.
Sources : newsletter.chiefmartec et databricks
