La sortie de Proxmox Virtual Environment (VE) 9.0 marque une avancée qualitative dans la manière dont les administrateurs systèmes peuvent surveiller et gérer les infrastructures virtualisées. L’une des nouveautés les plus significatives est l’intégration de Pressure Stall Information (PSI), une métrique avancée du noyau Linux qui mesure avec précision le temps que les processus passent en attente de ressources critiques telles que le CPU, la mémoire ou l’I/O.
Pour les administrateurs habitués aux outils comme htop, iostat ou aux moyennes de charge système, l’intégration de PSI dans Proxmox offre une visibilité beaucoup plus fine—et surtout, exploitable.
Qu’est-ce que le Pressure Stall Information (PSI) ?
Le Pressure Stall Information est un sous-système introduit dans le noyau Linux à partir de la version 4.20 (2018). Son objectif est de standardiser la façon dont le noyau quantifie le temps passé par les processus en attente d’un accès aux ressources.
En d’autres termes, lorsque les processus se disputent le CPU, la mémoire ou le disque, certains attendent. Jusqu’à présent, les administrateurs ne disposaient que de métriques indirectes : charge système, pourcentage d’utilisation CPU ou activité swap. PSI va plus loin en fournissant une mesure directe de la “pression” causée par la contention des ressources.
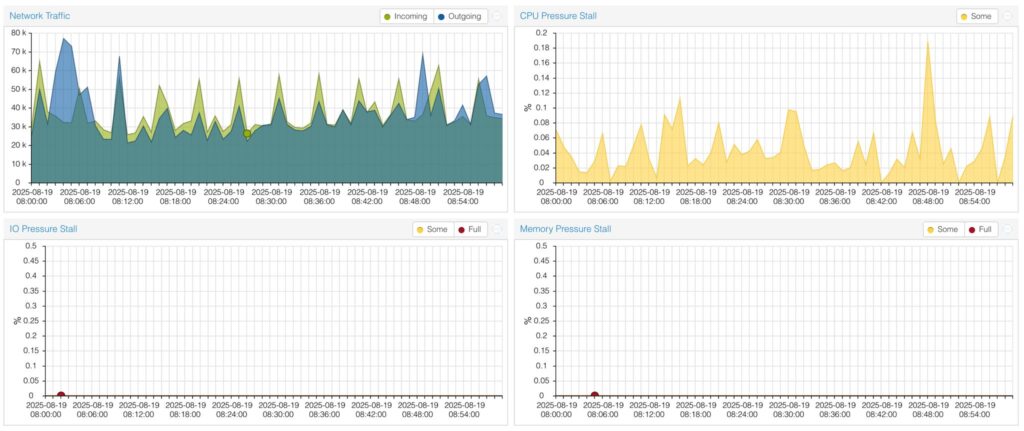
Dans Proxmox VE 9, PSI est intégré à l’interface web, permettant de surveiller :
- CPU pressure stall : temps passé par les tâches en attente de cycles CPU.
- Memory pressure stall : temps passé en attente de pages mémoire (ex. à cause du swap ou d’un manque de RAM).
- I/O pressure stall : temps passé en attente d’opérations disque ou réseau.
PSI vs. Métriques traditionnelles : un changement de paradigme
La manière la plus courante de mesurer la charge Linux a longtemps été la moyenne de charge (load average), qui indique le nombre de processus actifs ou en attente sur 1, 5 et 15 minutes. Mais cette métrique est difficile à interpréter dans des environnements virtualisés, car elle ne distingue pas la nature du goulet d’étranglement.
Avec PSI, la différence devient évidente :
| Métrique | Ce qu’elle mesure | Limites |
|---|---|---|
| Load average | Nombre moyen de processus actifs ou en file d’attente | Ne précise pas la ressource en cause. Peut sembler “élevée” même si le système reste réactif. |
| Utilisation CPU (%) | Pourcentage de temps d’exécution CPU | N’indique pas le temps d’attente des processus. |
| iostat / iotop | Activité disque et I/O | Montre l’usage mais pas l’impact sur les processus en attente. |
| PSI (CPU/Mem/I/O) | Temps bloqué en attente de CPU, RAM ou I/O | Direct, comparable, exploitable au niveau système, cgroup, VM ou conteneur. |
Exemple : un serveur peut afficher seulement 50 % d’utilisation CPU, mais PSI révèle que 25 % du temps des processus est bloqué sur l’I/O. Le véritable goulot est donc le stockage—ce qu’une moyenne de charge classique ne mettrait pas en évidence.
PSI dans Proxmox VE 9
L’intégration de PSI dans Proxmox VE 9 ne se limite pas à de nouvelles métriques : elle offre une visibilité opérationnelle. PSI est affiché graphiquement pour les nœuds physiques, les machines virtuelles et les conteneurs LXC, grâce au support de cgroups.
Principales fonctionnalités :
- Fenêtres temporelles allant de 1 minute à des vues historiques longues.
- Ventilation par type de ressource (CPU, mémoire, I/O).
- Corrélation avec les indicateurs traditionnels (CPU, RAM, disque).
De plus, Proxmox expose les valeurs PSI via son API, facilitant l’intégration dans des systèmes externes comme Prometheus, Zabbix ou Grafana.
Cas pratiques pour les administrateurs systèmes
Pour les sysadmins, PSI devient un outil puissant pour diagnostiquer et prévenir les problèmes. Quelques exemples :
1. Identifier les vrais goulets d’étranglement
Un nœud affiche 50 % d’utilisation CPU, mais PSI montre 25 % de blocages I/O. Le problème vient du stockage, pas du processeur.
2. Optimisation des ressources en cluster
Une VM présentant de fortes stalls mémoire peut dégrader d’autres workloads. PSI aide à réaffecter la RAM, appliquer des limites ou migrer la charge avant un impact global.
3. Ajustement QoS et cgroups
En surveillant PSI par conteneur, il est facile de repérer les “voisins bruyants” et de leur imposer des limites plus strictes.
4. Alertes précoces lors des pics de charge
PSI détecte l’augmentation des temps d’attente avant même qu’une panne survienne. Les admins gagnent du temps d’intervention.
5. Benchmarks plus réalistes
PSI complète les mesures de débit et latence, offrant une vision plus fidèle des performances.
Limites et pièges
Comme toute métrique, PSI a des limites :
- Valeurs résiduelles en idle : des tâches de fond (cron, journaling) peuvent générer du PSI non nul sur un système “au repos”.
- Pas une mesure d’utilisation directe : PSI mesure l’attente, pas l’usage. C’est complémentaire.
- Contexte nécessaire : 2 % de blocage peut être anodin pour un batch, mais critique pour une application temps réel.
Impact culturel sur la pratique sysadmin
L’ajout de PSI dans Proxmox VE 9 reflète une tendance plus large : passer de la simple surveillance à une observabilité avancée.
Dans un monde de conteneurs et microservices, il est essentiel de savoir non seulement combien une ressource est utilisée, mais aussi comment la contention impacte l’exécution des processus.
Pour les administrateurs systèmes, cela signifie évoluer d’une posture réactive vers une gestion proactive basée sur la donnée. PSI leur fournit des preuves concrètes pour justifier des mises à niveau, optimiser le placement des workloads ou négocier des SLA.
FAQ étendue pour administrateurs systèmes
1. Où sont stockées les métriques PSI dans Linux ?
Dans /proc/pressure/{cpu,memory,io}. Proxmox VE 9 les lit et les affiche dans son tableau de bord.
2. Quelle est la différence entre PSI au niveau nœud et au niveau cgroup ?
Au niveau nœud, PSI mesure la pression globale. Au niveau cgroup, il isole la pression par VM ou conteneur.
3. Peut-on intégrer PSI avec Prometheus ou Grafana ?
Oui. Proxmox expose PSI via son API. Des exporters existent pour Prometheus afin de construire des dashboards avancés.
4. PSI ajoute-t-il une charge au système hôte ?
Négligeable. Le noyau implémente PSI avec des mises à jour différées.
5. Comment interpréter un 10 % CPU stall ?
Cela signifie que sur la période mesurée, 10 % du temps des processus était passé en attente de CPU.
6. Quel est le lien entre PSI et l’ordonnanceur Linux ?
PSI n’altère pas l’ordonnancement, il l’observe. Il permet d’évaluer si l’ordonnanceur provoque des files d’attente excessives.
7. PSI peut-il aider à détecter des abus ou attaques ?
Indirectement oui. Une forte pression I/O dans un conteneur peut signaler un workload abusif ou mal configuré.
8. Quels outils externes complètent PSI ?psimon, cgroup2psi, exporters Prometheus. Ils exploitent PSI pour alerting et corrélation avec les logs.
9. Quand faut-il s’inquiéter de valeurs PSI élevées ?
Selon le SLA. Un 5 % I/O stall constant peut être critique pour une application web, mais tolérable pour un traitement batch.
10. PSI remplace-t-il la load average ?
Non, il la complète. La load average montre le nombre de processus en file, PSI montre combien de temps ils sont bloqués.
Conclusion
L’intégration du pressure stall information dans Proxmox VE 9 constitue une avancée majeure en matière d’observabilité des infrastructures. Pour les administrateurs systèmes, elle offre une compréhension fine des goulets d’étranglement, une prévention proactive des incidents et un support objectif pour leurs décisions techniques.
Dans un environnement où la milliseconde compte, PSI change la donne : il ne s’agit plus seulement de mesurer l’utilisation des ressources, mais l’impact sur les processus. Pour les sysadmins, ce n’est pas qu’une métrique : c’est un avantage stratégique.
via: LinkedIN, administración de sistemas
