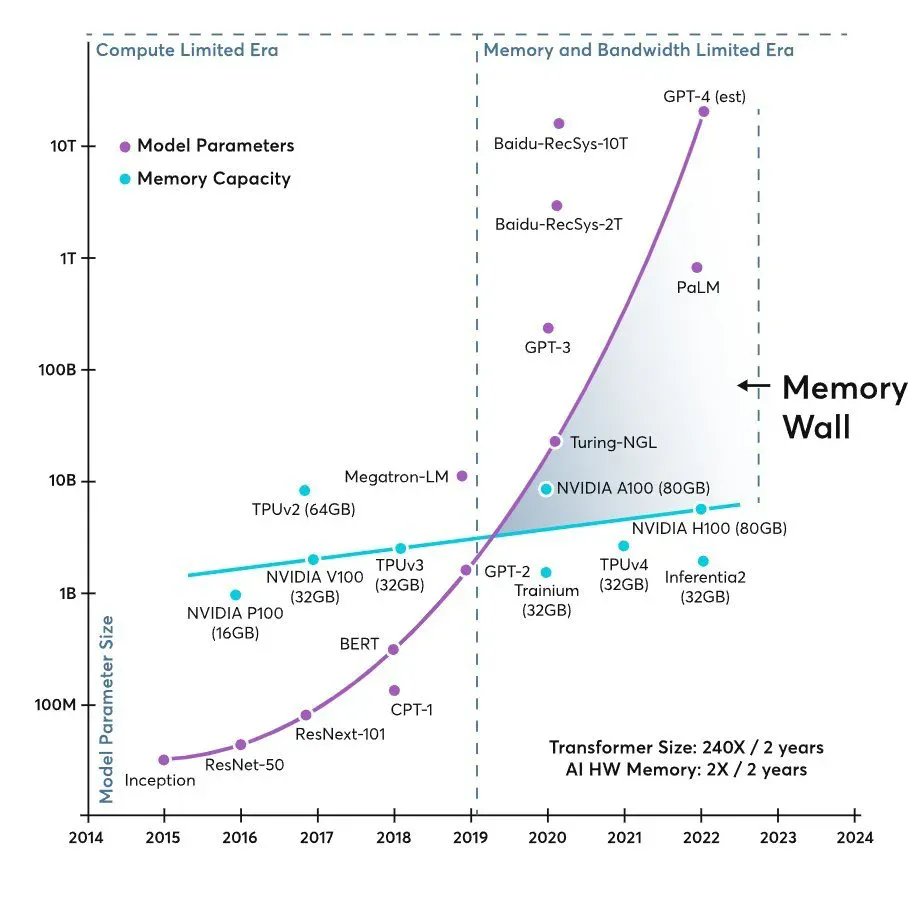
Depuis des années, la conversation sur l’infrastructure pour l’intelligence artificielle se résume à une idée simple : « il manque des GPU ». Mais en 2026, le goulet d’étranglement commence à se raconter différemment. Un graphique largement diffusé dans les cercles techniques et chez les investisseurs montre deux courbes qui s’écartent comme des ciseaux : la taille des modèles croît de manière quasi exponentielle, tandis que la mémoire disponible par accélérateur progresse à un rythme bien plus modeste. Le résultat reste le même dans tout centre de donnée : si le processeur graphique ne reçoit pas les données à la vitesse adéquate, sa puissance est sous-utilisée, même si le matériel est de dernière génération.
Cette tension se résume en un terme de plus en plus fréquent dans la littérature académique et les blogs spécialisés : “mural de la mémoire” ou « mémoire wall ». Il ne s’agit pas uniquement d’un « manque de mémoire », mais de l’ensemble de capacité, de bande passante et de latence nécessaires pour transférer les données entre la logique de calcul et les différents niveaux de mémoire (des cache embarqués jusqu’à la HBM ou la DRAM). Dans des modèles de type transformer — en particulier pour l’inférence —, la mémoire et son bandeau peuvent devenir le facteur prédominant face au calcul pur, avec un impact direct sur le coût, la consommation et la latence.
De l’ère du calcul à l’ère de l’alimentation de l’accélérateur
Le secteur a déjà vécu quelque chose de similaire dans la computation traditionnelle : des CPU toujours plus rapides attendant que la RAM leur fournisse des données. En IA, le scénario se répète, mais à une échelle industrielle. À mesure que les modèles grossissent, les exigences pour transférer paramètres, activations, embeddings et, en inférence, caches internes permettant de maintenir le contexte, s’accroissent également. Quand ce « train de données » n’arrive pas à temps, l’accélérateur passe une partie de son cycle à attendre.
Dans ce contexte, l’investissement commence à évoluer : il ne suffit pas d’ajouter plus de GPU ; il faut également concevoir des systèmes capables de les maintenir occupés, avec une mémoire plus proche, plus large et avec une capacité utilisable accrue. C’est pourquoi, dans les discussions techniques, de nombreuses sigles, auparavant presque invisibles pour le grand public, font leur apparition : HBM, CXL, hiérarchies de mémoire plus complexes, et architectures cherchant à réduire le coût de « déplacement des octets » par rapport à celui de « réaliser des opérations ».
HBM et DDR5 : la mémoire revient au centre du design
La High Bandwidth Memory (HBM) est devenue le symbole de cette nouvelle étape car elle cible directement la problématique principale : bande passante par watt et proximité physique avec le processeur. Les fabricants de mémoire positionnent leurs gammes avancées comme indispensables pour l’entraînement des modèles exigeants, tout en réservant la DDR5 pour la scalabilité et le coût dans des configurations plus généralistes. Dans leur documentation technique, Micron Technology met en avant la HBM3E et la DDR5 pour les charges d’entraînement, proposant également des modules d’expansion basés sur CXL comme solution pour augmenter la capacité au-delà des canaux directs, lorsque le problème est le « volume total » des datasets ou des modèles.
Cette stratégie illustre une idée de plus en plus acceptée : l’avenir immédiat ne consiste pas à choisir « une seule mémoire », mais à mixer les couches (HBM pour la vitesse, DDR pour le volume, et extensions comme CXL pour augmenter sans refaire toute la plateforme). Dans la pratique, cela se traduit par des racks plus complexes, et aussi par une dépendance accrue à la chaîne d’approvisionnement en mémoire avancée.
L’autre gros acteur : la mémoire flash pour les checkpoints et le stockage rapide
Le débat ne s’arrête pas à la HBM. Les flux d’entraînement et de service pour les grands modèles dépendent aussi de checkpoints , de datasets massifs et de stockage local rapide pour éviter que le cluster ne devienne une machine de « pause disque ». La demande pour la NAND et les SSD d’entreprise est en forte augmentation, non seulement pour la capacité, mais aussi pour les performances soutenues et la prévisibilité des latences.
Sur ce front, le rôle de SanDisk refait surface après sa scission de l’entreprise, finalisée le 24 février 2025, qui en a fait une entité indépendante cotée sous le ticker SNDK. Dans leurs résultats récents, plusieurs médias financiers ont lié la croissance des revenus et des bénéfices à la demande croissante en IA et à la pression sur l’offre, parlant même de contrats pluriannuels et de prix plus stables pour sécuriser l’approvisionnement.
Pour un média technologique, la lecture est pragmatique : à mesure que les modèles deviennent plus grands, le « backstage » de l’entraînement et de l’inférence se professionnalise. L’IA ne vit pas seulement dans le chipset ; elle habite tout le pipeline, de la mémoire ultra-rapide au stockage qui contient datasets, checkpoints et artefacts de déploiement.
Micron, investissement et capacité : la mémoire comme enjeu industriel
La pression se ressent non seulement dans le catalogue de produits, mais aussi à travers d’importants investissements. En janvier 2026, Reuters annonçait que Micron prévoit d’investir 24 milliards de dollars dans une nouvelle usine à Singapour pour répondre à la pénurie mondiale de mémoire liée à la montée en puissance des applications IA et des charges « data-centric ». La même source indiquait que Singapour concentre déjà une bonne partie de la production de flash de l’entreprise, avec une unité avancée de packaging pour la HBM évaluée à 7 milliards de dollars, avec une contribution attendue à partir de 2027.
Au-delà du détail géographique, le message est clair : la mémoire devient un composant stratégique, et non un simple accessoire. Quand l’industrie se positionne ainsi, l’impact se prolonge sur la disponibilité, les prix, les délais de livraison et les choix d’architecture dans les centres de données.
Les hyperscalaires et le coût de maintenir la GPU « à faim zéro »
Les grands opérateurs cloud — Google, Amazon, Meta et Microsoft — rivalisent pour entraîner et déployer des modèles de plus en plus ambitieux. La narration habituelle évoque des achats massifs d’accélérateurs NVIDIA, mais dans la pratique, le vrai défi est de maintenir une « usine » où les puces restent occupées la majorité du temps.
En ce sens, la « mur de mémoire » en tant que métaphore est utile : d’un côté, l’industrie célèbre l’émergence de modèles plus volumineux (y compris des estimations non officielles attribuées à OpenAI), de l’autre, le matériel nécessite davantage de mémoire et une bande passante accrue pour que cette taille soit exploitable efficacement. Si le système n’alimente pas bien, la solution n’est pas forcément d’acheter plus de GPU, mais d’augmenter la mémoire par accélérateur, d’améliorer le réseau interne et d’optimiser la fluidité des transferts de données.
La prochaine étape : l’architecture, pas uniquement la puissance brute
Ce qui émerge comme la tendance la plus intéressante aujourd’hui, c’est que l’innovation se déplace vers l’architecture du système : comment distribuer les paramètres, gérer la cache en inférence, réduire le trafic mémoire ou déplacer moins d’informations pour obtenir le même résultat. La « mur de mémoire » ne se détruit pas avec une seule pièce, mais par un ensemble : HBM plus performant, interconnexions optimisées, stockage local rapide, et des designs qui considèrent que « déplacer des données » est le nouveau luxe.
À court terme, la conséquence la plus visible sera : les centres de données IA tendront à devenir plus coûteux, plus complexes, mais aussi plus optimisés. Dans cette dynamique, la mémoire — HBM et flash — cesse d’être un simple complément pour devenir le pivot qui décide si un cluster fonctionne à 30 % ou exploite pleinement son potentiel.
Questions fréquemment posées
Que signifie exactement “mural de la mémoire” dans les modèles de langage, et pourquoi affecte-t-il autant l’inférence ?
Le « mural de mémoire » désigne le point où la performance est limitée par la capacité, la latence ou la bande passante mémoire, et non par le calcul. En inférence, la nécessité de maintenir et de déplacer des données de contexte et des structures internes peut transformer la mémoire en le goulot d’étranglement principal.
Le HBM3E est-il indispensable ou la DDR5 reste-t-elle valable pour l’IA ?
Le HBM3E est généralement utilisé lorsque l’objectif est une bande passante maximale et une efficacité énergétique pour un entraînement de très haut niveau. La DDR5 reste très utile en raison de son coût et de sa scalabilité, notamment dans les configurations où la capacité totale prime sur le pic de performance.
Quel rôle joue la mémoire flash (SSD/NVMe) dans les centres de données IA ?
La mémoire flash est essentielle pour le stockage rapide des datasets, checkpoints et opérations nécessitant un I/O soutenu. Un système de stockage lent peut freiner les pipelines d’entraînement et les déploiements, même avec des GPU puissants.
Comment CXL s’intègre-t-il dans la stratégie pour pallier le manque de mémoire dans les serveurs IA ?
CXL permet d’étendre la capacité mémoire de manière plus flexible que les canaux traditionnels, offrant une voie pour augmenter le volume lorsque le problème ne concerne plus uniquement la bande passante, mais aussi la capacité totale nécessaire pour les données et modèles.
vía : X Twitter
