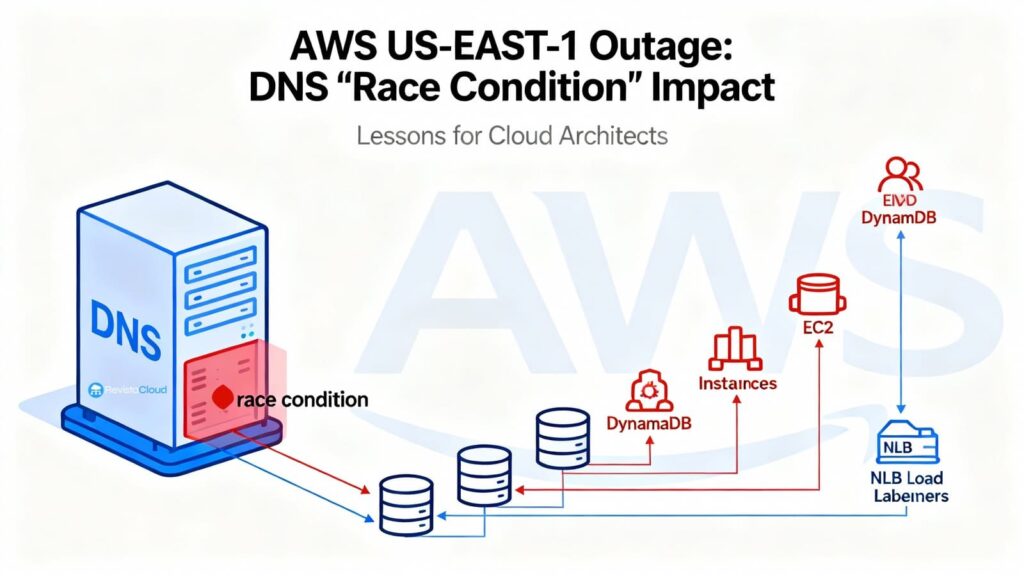
AWS a publié le rapport détaillant la post-mortem de l’incident survenu les 19 et 20 octobre qui a mis hors service la région N. Virginia (us-east-1) et affecté de nombreux services. La cause était aussi subtile que dévastatrice : une condition de course (race condition) dans l’automatisation interne de gestion des DNS d’Amazon DynamoDB. Ce bug a conduit à l’application d’un plan DNS vide sur l’endpoint régional dynamodb.us-east-1.amazonaws.com, empêchant sa résolution. Sans le « catalogue » coordonnant une grande partie du contrôle d’AWS, la propagation d’erreurs a été immédiate : IAM, STS, EC2, Lambda, NLB, ECS/EKS/Fargate, Redshift et d’autres services ont enchaîné les défaillances pendant plusieurs heures.
L’entreprise reconnaît avoir dû mettre en pause l’automatisation globale, restaurer manuellement l’état du DNS pour DynamoDB, puis procéder à un déblocage progressif via des redémarrages ciblés et une limitation temporaire des requêtes afin de récupérer la région étape par étape. Le rapport officiel précise le déroulement, les causes et les mesures qui seront prises pour éviter que cela ne se reproduise.
Chronologie d’un effondrement (vue d’ensemble)
AWS identifie trois fenêtres principales d’impact (heure locale du Pacifique, PDT) :
- 19/10, 23:48 – 20/10, 02:40 : DynamoDB subit une hausse d’erreurs d’API. Les clients et services internes à AWS dépendant de DynamoDB ne peuvent pas établir de nouvelles connexions car l’endpoint régional ne se résout plus.
- 20/10, 02:25 – 10:36 : le lancement de nouvelles instances EC2 échoue pendant des heures ; quand cela commence à fonctionner, certaines instances récentes n’ont pas de connectivité en raison de retards dans la propagation de leur état réseau.
- 20/10, 05:30 – 14:09 : Network Load Balancer (NLB) enregistre des erreurs de connexion sur une partie de la flotte en raison de faux positifs dans les vérifications de santé : il met en service des capacités dont le réseau n’est pas complètement propagé. Les vérifications fluctuent et la couche d’orchestration désactive et réactive des nœuds DNS, dégradant ainsi le plan de données.
Parallèlement, des services tels que Lambda (invocations et event sources), ECS/EKS/Fargate (démarrage de conteneurs et scaling), Amazon Connect (gestion des appels/chats), STS (émission de crédentials temporaires) et même Redshift (requêtes et modifications de clusters) ont été impactés en dépendant directement ou indirectement de DynamoDB, des lancements EC2, ou du fonctionnement correct du NLB.
La racine du problème : Planner, Enactor… et un vide DNS
DynamoDB gère des centaines de milliers d’enregistrements DNS par région pour diriger le trafic vers une diversité de balanceurs (et variantes comme endpoints publics, FIPS, IPv6, endpoints par compte, etc.). Cette complexité est encadrée par deux modules :
- DNS Planner : calcule périodiquement un plan DNS pour chaque endpoint (liste de balanceurs et poids) basé sur la capacité et la santé.
- DNS Enactor : applique ces plans dans Amazon Route 53 via des transactions atomiques. Par résilience, il y a trois Enactors, un dans chaque AZ, opérant en parallèle et de manière indépendante.
Le bug apparaît lorsqu’un Enactor retardataire tente d’appliquer un ancien plan en même temps qu’un Enactor à jour, qui termine de déployer un plan récent et lance le nettoyage de plans obsolètes. La séquence, improbable mais possible, fut la suivante :
- L’Enactor retardataire écrase sur l’endpoint régional le plan récent avec un plan obsolète (la vérification “ce plan est plus récent” devient obsolète à cause du retard).
- L’Enactor à jour procède à la nettoyage et supprime le plan ancien, considéré comme trop vieux.
- Conséquence : l’endpoint régional ne possède plus d’adresses DNS et le système entre dans un état incohérent qui bloque toute correction automatique ultérieure.
- Solution : une intervention manuelle pour restaurer l’état correct dans Route 53 et débloquer le cycle.
À partir de ce moment, tout ce qui dépendait de DynamoDB a commencé à échouer.
EC2 : pourquoi ne pouvait-on pas lancer de nouvelles instances même “Dynamo était revenu”
Une fois le DNS de DynamoDB restauré, il restait à récupérer le plan de contrôle d’EC2. Deux composants internes jouent ici :
- DropletWorkflow Manager (DWFM) : gère les serveurs physiques (droplets) hébergeant les instances EC2, maintenant un « bail » (lease) actif pour chaque droplet.
- Network Manager : propage l’état réseau (routages, règles, attachments) vers les instances et appliances.
Durant la panne DynamoDB, les contrôles périodiques de DWFM échouaient pour leurs droplets<, et les leas expiraient progressivement. Avec DynamoDB revenu, DWFM tenta de reprendre des millions de leases simultanément ; la chute fut si massive que le système entra en effet de congestion (files de requêtes qui se réentraînent, expirations en cascade). La méthode de récupération classique SRE (Site Reliability Engineering) fut de faire du limiting (throttling) et des redémarrages ciblés pour libérer les files et réduire la latence. Avec les leases rétablis, les déploiements ont pu continuer.
Il restait le Network Manager : il devait propager l’état réseau à toutes les nouvelles instances, y compris celles déployées durant l’incident. La surcharge engendra des décalages : ces nouvelles instances démarraient sans connectivité jusqu’à ce que leur configuration atteigne leur système, ce qui a perturbé le check de santé du NLB, provoquant un flapping (oscillation d’état) et des configurations de capacité instables.
Pour calmer la situation, AWS désactiva temporairement le failover automatique du NLB, restaurait la capacité, puis l’a réactivé une fois la stabilité retrouvée.
Autres impacts majeurs
- Lambda : erreurs initiales liées à DynamoDB (créations, mises à jour, triggers SQS/Kinesis). Plus tard, avec EC2 dégradé, AWS a priorisé les invocations synchrones et limité mappages de sources d’événements et traitements asynchrones pour éviter la cascade de défaillances.
- STS et IAM : erreurs d’authentification et augmentations de latence (dépendance indirecte à DynamoDB, puis au NLB).
- Amazon Connect : défauts dans les appels, messageries et dashboards liés aux perturbations du NLB et Lambda.
- Redshift : interruptions dans les requêtes et opérations de clusters ; certains clusters en état “en modification” car impossibilité de remplacer certains hôtes EC2 pendant des heures. Un autre souci concernait les requêtes utilisant des crédentials IAM dans toutes les régions, dépendant d’une API IAM en us-east-1 pour résoudre des groupes, ce qui a impacté uniquement les clusters avec utilisateurs locaux.
Les mesures qu’AWS prévoit de mettre en œuvre
Le rapport annonce plusieurs actions concrètes :
- Automatisation DNS de DynamoDB (Planner/Enactor) désactivée globalement jusqu’à correction du problème de condition de course et implémentation de barrages supplémentaires pour empêcher l’envoi de plans erronés.
- NLB : contrôle de débit pour limiter la capacité que peut retirer un seul NLB lors de défaillances de health check et basculements AZ.
- EC2 : nouvelle génération de tests pour simuler la récupération à grande échelle de DWFM et renforcer la gestion du throttling lors de propagations de données, adaptant le rythme selon la taille des files pour éviter la surcharge.
Leçons pour architectes et SRE : anticiper la perte du « catalogue »
- Ne pas se limiter au multi-AZ ; envisager le multi-région (et multi-fournisseur si possible).
Si la disponibilité est critique, privilégiez des stratégies actives-actives ou en pilotage dans une autre région. Pour DynamoDB, Global Tables aide… mais le trafic vers un endpoint regional défaillant ne basculera pas seul : l’application doit connaître les réplicas et accepter un certain retard. - Distinguer data plane et control plane dans le design.
Votre application peut continuer à fonctionner si le plan de données reste stable, même si le plan de contrôle est dégradé (création d’instances, mise à jour de configs, élévation de crédits). Disposez-vous de capacités « hot » ou d’un pool d’instances pour absorber la charge, ou pouvez-vous dégrader certaines fonctions? - DNS : mise en cache raisonnable, éviter l’extrême.
Un TTL bien choisi amortit les pannes transitoires. Évitez les TTL à 0 ou très longs ; lorsque le fournisseur corrige l’endpoint, vous ne souhaitez pas attendre des heures pour la mise à jour. En environnements critiques, privilégiez les stratégies de retries avec backoff et ne fixez pas d’IP unique pour des services managés. - Vérifications de santé avec patience (pour éviter le flapping).
Fixez des seuils et périodes de grâce afin d’éviter des bascules causées par des vérifications transitoires durant des propagations de réseau. Un failover trop agressif peut provoquer la suppression de nœuds sains. - Interrupteurs de circuit (circuit breakers) et routes de dégradation.
En cas de défaillance, limitez les opérations critiques (lecture seule, accumulation locale, pause des composants non essentiels). - Gestion des crédentials et sessions.
Évitez les expirations simultanées de tokens et, en cas de latence sur STS/IAM, ne pas tenter de renouveler tout en même temps. Scindez et rallongez les marges lors d’incidents. - Runbooks et exercices « us-east-1 down ».
Documentez précisément qui fait quoi, dans quel ordre : désactivation, modification de DNS, basculement région, priorisation des queues, etc. Faites régulièrement des simulations.
Virginia, le « canari » d’AWS ?
Dans les forums techniques, une idée revient : us-east-1 est la région la plus grande, ancienne et avec le plus grand nombre de services en production. Elle serait, par conséquent, plus vulnérable aux incidents complexes et aux déclenchements systémiques. Certains la nomment le « canari » d’AWS. Plus pragmatiquement, cela signifie : ne concentrez pas toutes vos dépendances critiques uniquement dans cette région, notamment pour le plan de contrôle et les points de coordination clés. Concevez votre architecture pour la résilience en acceptant qu’une région, même la plus emblématique, peut tomber en panne ou devenir inaccessible pendant plusieurs heures, indépendamment de votre conception.
Ce qu’il faut dire à son organisation et à ses clients
- Ce qui s’est passé (dates, services impactés, durée)
- Les mesures de contingence appliquées et les risques résiduels (retards, ret發out, backlog)
- Les actions prévues à court/moyen terme : gestion-dechange, multi-région, TTL DNS, vérifications de santé, throttling, capacités pré-allouées ; avec dates et responsables.
- Comment seront évalués les progrès : indicateurs de continuité, RTO/RPO, objectifs de résilience.
Conclusion
L’incident de us-east-1 n’était pas une « tempête parfaite » issue du hasard : il reflète un défaut de course dans un système critique et automatisé (la gestion DNS d’un service central), qui, une fois activé, a évacué un endpoint et bloqué la capacité d’auto-réparation. Ensuite, tout s’enchaîne avec les dégradations croisées et la congestion typique des architectures à très grande échelle. La bonne nouvelle est que le rapport offre des actions concrètes à mettre en œuvre ; la moins bonne, c’est qu’il n’y a pas de magie : la résilience ne se décrète pas, elle se conçoit. Et cela commence par accepter qu’une région – même celle la plus célèbre – peut tomber en panne, même hors de votre contrôle direct.
Foire aux questions
Comment atténuer l’impact d’une panne régionale AWS pour un e-commerce ou un média digital ?
Utilisez des architectures multi-AZ et multi-région pour le frontend et les services critiques (cache/CDN, authentification, catalogue). Exploitez DynamoDB Global Tables ou des réplicas gérés, et configurez votre application pour basculer vers ces réplicas ou régions en cas de panne, tout en maintenant une capacité « hot ».
Pourquoi le Network Load Balancer a-t-il échoué si DynamoDB était seul impacté ?
Parce qu’après restauration du DNS DynamoDB, EC2 a mis du temps à réinitialiser ses leases et à propager la configuration réseau. Le NLB a commencé à mettre en service des nœuds avant que leur connectivité ne soit prête, causant des fluctuations dans les vérifications de santé et des défaillances automatiques de capacité.
Faut-il réduire le TTL DNS pour un rétablissement plus rapide ?
Un TTL modéré permet d’atténuer les coupures brèves. Évitez TTL à 0 ou très longs ; privilégiez aussi les retries avec backoff et ne fixez pas d’IPs.
Est-il pertinent d’éviter us-east-1 ?
Il vaut mieux diversifier. Exploitez la multi-région, la gestion de dégradation contrôlée et la commutation régionale pour limiter l’impact d’un incident majeur dans une seule région.
Sources : Post-Event Summary de AWS décrivant l’incident DynamoDB, ses impacts sur EC2, NLB et autres services en N. Virginia (us-east-1), ainsi que la documentation technique relative.
