Dynatrace (NYSE : DT), leader en observabilité et sécurité unifiées, a annoncé le lancement d’OpenPipeline®, une nouvelle technologie centrale qui offre aux clients un pipeline unique pour gérer l’ingestion de données à l’échelle du pétaoctet sur la plateforme Dynatrace® qui propulse l’analytique, l’IA et l’automatisation de manière sûre et rentable.
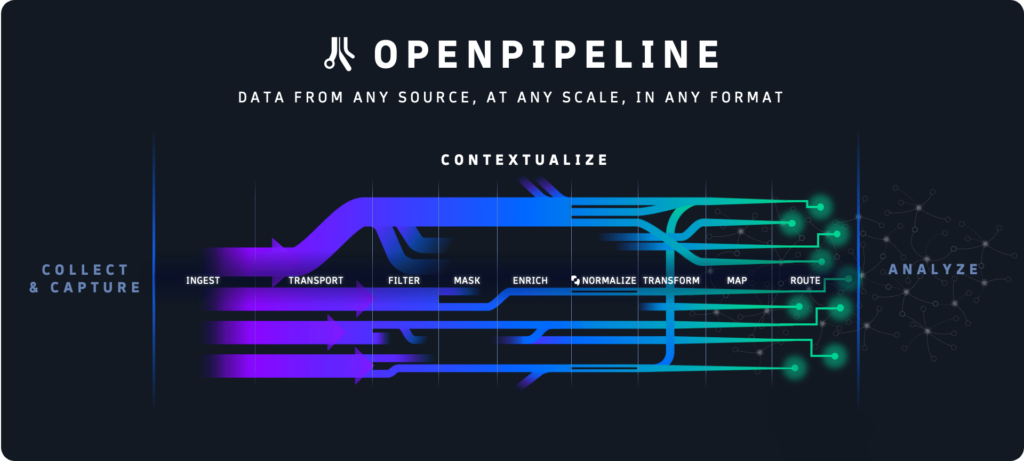
OpenPipeline® de Dynatrace offre aux équipes commerciales, de développement, de sécurité et d’exploitation une visibilité et un contrôle totaux sur les données qu’elles ingèrent dans la plateforme Dynatrace®, tout en préservant le contexte des données et des écosystèmes cloud où elles prennent origine. De plus, il évalue les flux de données entre cinq et dix fois plus rapidement que les technologies héritées. En conséquence, les organisations peuvent mieux gérer le volume croissant et la variété des données émanant de leurs environnements hybrides et multicloud, et permettre à plus d’équipes d’accéder aux réponses et automatisations impulsées par l’IA de la plateforme Dynatrace, sans besoin de recourir à des outils supplémentaires.
« Les données sont l’éssence de notre entreprise. Elles contiennent des informations précieuses et automatisent les processus, libérant ainsi nos équipes de tâches plus mécaniques », déclare Alex Hibbitt, Directeur de l’Ingénierie, SRE et Fulfillment, chez albelli-Photobox Group. « Cependant, nous faisons face à des défis lors de la gestion de nos pipelines de données de manière sécurisée et rentable. L’addition d’OpenPipeline à Dynatrace étend la valeur de la plateforme. Cela nous permet de gérer des données provenant d’un large éventail de sources en parallèle des données en temps réel collectées de manière native sur Dynatrace, le tout sur une seule plateforme, ce qui facilite la prise de décisions mieux informées. »
Selon Gartner®, « les charges de travail actuelles génèrent des volumes de plus en plus importants – des centaines de téraoctets et même des pétaoctets chaque jour – de télémétrie provenant de diverses sources. Cela menace de submerger les opérateurs responsables de la disponibilité, de la performance et de la sécurité. Le coût et la complexité associés à la gestion de ces données peuvent dépasser les 10 millions de dollars par an dans les grandes entreprises. »
Créer un pipeline unifié pour gérer ces données est un défi en raison de la complexité des architectures cloud modernes. Cette difficulté, et la prolifération des outils de surveillance et d’analyse dans les organisations, peuvent épuiser les budgets. En même temps, les entreprises doivent se conformer à une série de normes de sécurité et de confidentialité, telles que le RGPD et l’HIPAA, en relation avec leurs pipelines de données, analyses et automatisations. Malgré ces défis, les parties prenantes de toutes les organisations cherchent plus d’informations basées sur les données et d’automatisation pour prendre de meilleures décisions, améliorer la productivité et réduire les coûts. Par conséquent, elles ont besoin d’une visibilité et d’un contrôle clairs des données, tout en gérant les coûts et en maximisant la valeur de leurs solutions d’automatisation et d’analyse de données existantes.
OpenPipeline de Dynatrace travaille avec d’autres technologies centrales de la plateforme Dynatrace, y compris le Grail™ data lakehouse, la topologie Smartscape®, et l’hypermodal IA Davis®, pour relever ces défis en offrant les avantages suivants :
· Analyse de données à l’échelle du pétaoctet : Exploite les algorithmes de traitement de flux en attente de brevet pour obtenir des rendements de données significativement plus élevés à l’échelle du pétaoctet.
· Ingestion de données unifiée : Permet aux équipes d’ingérer et d’améliorer l’acheminement des données d’observabilité, de sécurité et d’événements commerciaux – y compris la Qualité de Service (QoS) dédiée pour les événements d’affaires – depuis n’importe quelle source et dans n’importe quel format, comme Dynatrace® OneAgent, les API de Dynatrace et OpenTelemetry, avec des temps de rétention personnalisables pour des cas d’utilisation individuels.
· Analyse de données en temps réel à l’ingestion : Permet aux équipes de transformer des données non structurées en formats structurés et utilisables au point d’ingestion, par exemple, en transformant des données brutes en séries temporelles ou en données de métriques et en créant des événements commerciaux à partir de lignes de journal.
· Contexte de données complet : Enrichit et préserve le contexte de points de données hétérogènes – y compris des métriques, traces, logs, comportements des utilisateurs, événements commerciaux, vulnérabilités, menaces, événements du cycle de vie et de nombreux autres – qui reflètent les différentes parties de l’écosystème cloud d’où elles proviennent.
· Contrôles pour la confidentialité et la sécurité des données : Offre aux utilisateurs le contrôle sur les données qu’ils analysent, stockent ou excluent des analyses et comprend des contrôles de sécurité et de confidentialité entièrement personnalisables, comme le masquage automatique et basé sur les fonctions PII pour aider à satisfaire les besoins spécifiques et les exigences réglementaires des clients.
· Gestion de données rentable : Aide les équipes à éviter l’ingestion de données dupliquées et réduit les besoins de stockage en transformant les données en formats utilisables – par exemple, de XML a JSON – et permettant aux équipes d’éliminer les champs inutiles sans perdre aucune information, contexte ou flexibilité d’analyse.
« OpenPipeline est un ajout puissant à la plateforme Dynatrace », déclare Bernd Greifeneder, CTO de Dynatrace. « Il enrichit, converge et contextualise des données hétérogènes d’observabilité, de sécurité et de commerce, fournissant des analyses unifiées pour ces données et les services qu’elles représentent. De même que pour Grail data lakehouse, nous avons conçu OpenPipeline pour l’analyse à l’échelle du pétaoctet. Il fonctionne avec l’IA hypermodale Davis de Dynatrace pour extraire des informations significatives des données, stimulant une analyse robuste et une automatisation fiable. Basé sur nos tests internes, nous croyons qu’OpenPipeline, propulsé par l’IA Davis, permettra à nos clients d’évaluer les flux de données entre cinq et dix fois plus rapidement que les technologies héritées. Nous croyons aussi que la convergence et la contextualisation des données au sein de Dynatrace facilitent la conformité réglementaire et les audits, tout en donnant le pouvoir à davantage d’équipes au sein des organisations d’avoir une visibilité immédiate sur la performance et la sécurité de leurs services numériques. »
OpenPipeline de Dynatrace devrait être disponible pour tous les clients SaaS de Dynatrace dans un délai de 90 jours à compter de cette annonce, en commençant par la compatibilité avec les journaux, métriques et événements commerciaux. Par la suite, d’autres types de données seront pris en charge.
